
Abstract
Exploring intelligent AI in Tic-Tac-Toe with Minimax, MaxN, Paranoid, Alpha-Beta, and Monte Carlo Tree Search.
This is the first of a series of expected interludes for the overall Multi-Part Series: Road to JDK 25 — Over-Engineering Tic-Tac-Toe.
Previously: Introduction to JDK 23
So far our primary task has been to progressively over-engineer tic-tac-toe (available for your pleasure at the overengineering-tictactoe GitHub repository: here) focused primarily on using finalized features from Java Enhancement Proposals).
In this article, though, we’ll take a break — or rather, a massive side quest from JDK enhancements to zoom in improve upon and explore the primary algorithms used in the game and look at a few used in game theory in general. It’s an interesting (even if a bit niche) diversion but worth the time especially with the rather long wait to JDK 24.
If you’re not familiar with Java, no need to worry — the code is intentionally written in a way that reads language neutral. All you have to do is wrap your head around all of the recursion!
Quick Note:
If you’ve been following the series through GitHub, you’ll note the classes have had a significant cleanup/refactor since the last update for JDK 23. The new
GameStateclass captures the current player, current board, last move and has methods to understand if moves are available in the game or not which proxy some of those previously found inGameBoard.
//
// https://github.com/briancorbinxyz/overengineering-tictactoe
// GameState.java - key method signatures
//
public record GameState(
GameBoard board,
List<String> playerMarkers,
int currentPlayerIndex,
int lastMove
) {
public GameState(GameState state);
public String currentPlayer();
public boolean hasMovesAvailable();
public boolean hasChain(String player);
public List<Integer> availableMoves();
public boolean isTerminal();
public GameState afterPlayerMoves(int move);
public boolean lastPlayerHasChain();
private String lastPlayer();
public int lastPlayerIndex();
}Tic-Tac-Toe
Tic-tac-toe is a simple game usually played by two players who take turns marking the spaces in a three-by-three grid with X or O. The player who successfully places three of their marks in either a horizontal, vertical, or diagonal row is the winner.
It is what’s known as a zero-sum game. In a zero-sum game, whatever one player gains, the other player loses. There’s a fixed amount of “win” to go around, so if you win, your opponent loses an equal amount — and vice versa. In other words, the sum of gains and losses between players is always zero.
Here’s why this matters: in a zero-sum game, your goal isn’t just to win — it’s to make sure your opponent doesn’t win. Every move you make either increases your chances of victory or limits your opponent’s.
Algorithm Level 1
Random Strategy
Imagine you’re playing tic-tac-toe, but instead of thinking about strategy, you decide to make your moves randomly — just picking any available square without a plan. Sometimes you might win by chance, but other times, you’ll lose because you didn’t consider what your opponent might do next. It’s like flipping a coin, or casting die in a game where strategy is everything.
That’s exactly what our first bot implementation did; it naively picked moves from those available at random in the vein hope that it would win, mimicking the strategy of a tic-tac-toe newbie:
public final class Random implements BotStrategy {
private final RandomGenerator random;
private final GameState state;
public Random(GameState state) {
this.state = state;
this.random = new SecureRandom();
}
@Override
public int bestMove() {
var availableMoves = state.board().availableMoves();
return availableMoves.get(random.nextInt(availableMoves.size()));
}
}How does it work? Rather simply. Given a player and a board (part of the game state), it simply picks a random move from the list of board.availableMoves() .
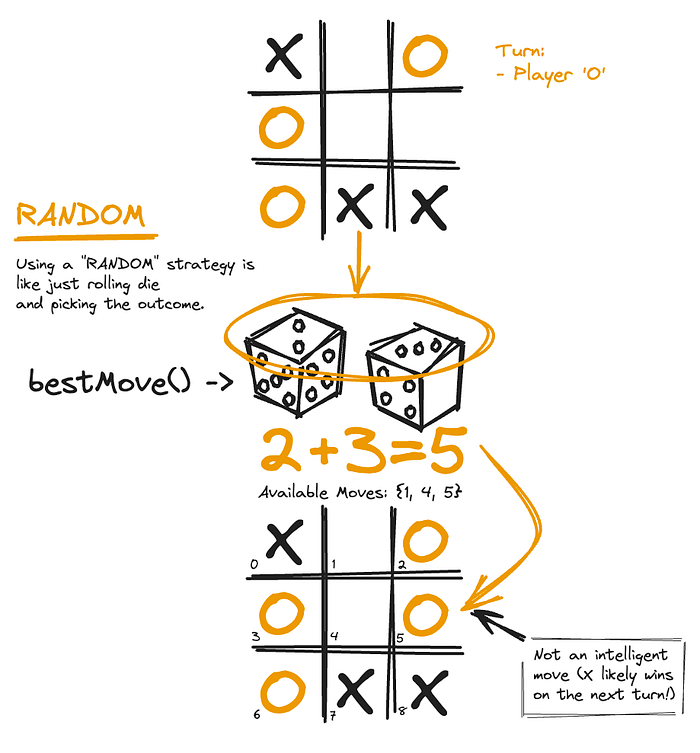
Tic-Tac-Toe using a “Random” strategy for choosing the next best move
More often than not, though, picking moves at random proves to be a losing strategy against any experienced opponent.
But what if you could improve on that pure randomness with a strategy so powerful it’s like having a genius guiding your every move? Enter the minimax algorithm — a zero-sum method that transforms your gameplay from random guessing to calculated genius.
Algorithm Level 2
Minimax Strategy
Minimax is designed specifically for zero-sum games like tic-tac-toe. It’s a strategy that helps you navigate the game by maximizing your minimum gains and minimizing your maximum losses.
In a zero-sum context, this means you’re always trying to increase your share of the “win” while reducing your opponent’s.
Here’s how it works:
- Planning Ahead: Instead of making random moves, minimax considers every possible move you can make and imagines what your opponent might do in response. It looks several steps ahead to predict the outcome of each potential path.
- Scoring Outcomes: Minimax assigns a score to each possible outcome — e.g.
+100if you win (maximum gain),-100if you lose (maximum loss), and0if it’s a tie. In a zero-sum game, these scores reflect the perfect balance of victory and defeat between you and your opponent (a maximum loss for you is a maximum gain for your opponent and vice-versa). - Choosing the Best Move: With all possible outcomes in mind, minimax picks the move that guarantees you the best possible result, even if your opponent plays perfectly. It’s like finding the safest path through a battlefield, ensuring that you always come out on top or, at the very least, avoid defeat.
In a random strategy, you might accidentally give your opponent the upper hand without realizing it. But with minimax, every move is carefully calculated to maximize your advantage while minimizing your opponent’s chances of success.
In a zero-sum game like tic-tac-toe, this kind of strategic thinking is crucial if you want to win. There’s no room for mistakes because every loss you suffer is a direct gain for your opponent. Minimax helps you navigate this balance, ensuring that you’re always making the smartest possible move.
How does it work? The genius is encapsulated in the Minimax class. This class is like a super-intelligent brain for a game-playing AI. It’s constantly asking, “What’s the absolute best move I, the maximizer, can make right now?” And it doesn’t just think one step ahead — it’s thinking ALL the steps ahead — It’s like a time machine for games!
The class takes the current game board and like Dr. Strange plays out EVERY possible future — every move, every countermove, all the way to the end of the game. It’s like having an all-seeing eye that shows all possible futures!
private int minimax(GameState state, boolean isMaximizing, int depth) {
if (state.hasChain(maximizer)) {
return MAX_SCORE - depth;
} else if (state.hasChain(opponent(maximizer))) {
return MIN_SCORE + depth;
} else if (!state.hasMovesAvailable() || config.exceedsMaxDepth(depth)) {
return DRAW_SCORE;
}
if (isMaximizing) {
int value = -Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = minimax(newState, false, depth + 1);
value = Math.max(value, score);
}
return value;
} else {
int value = Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = minimax(newState, true, depth + 1);
value = Math.min(value, score);
}
return value;
}
}But wait, there’s more! As it’s exploring all these possible futures, it’s keeping score. Winning moves get high scores, whilst losing moves get low scores. And here’s the clever bit: it assumes both players are playing their absolute best. So it’s always prepared for the toughest competition!
Now, the key part is the bestMove() method. This is where all that future-gazing pays off. It looks at all the possible next moves determined by minimax(), figures out which one leads to the best possible future, and says, “That’s the one! That’s the best move!”
// Minimax.java
public int bestMove() {
int bestMove = -1;
int maxScore = -Integer.MAX_VALUE;
for (int move : initialState.availableMoves()) {
var newState = initialState.afterPlayerMoves(move);
int score = minimax(newState, false, 0);
log(move, score, 0);
if (score > maxScore) {
maxScore = score;
bestMove = move;
}
}
return bestMove;
}Also get this — it even has a built-in preference for quick wins! (by tracking the depth ) If it sees two paths to victory, it’ll choose the faster one. i.e. a win now (lesser depth) is preferred over a win later (greater depth), and a loss later (greater depth) is preferred over a loss now (lesser depth). How cool is that?
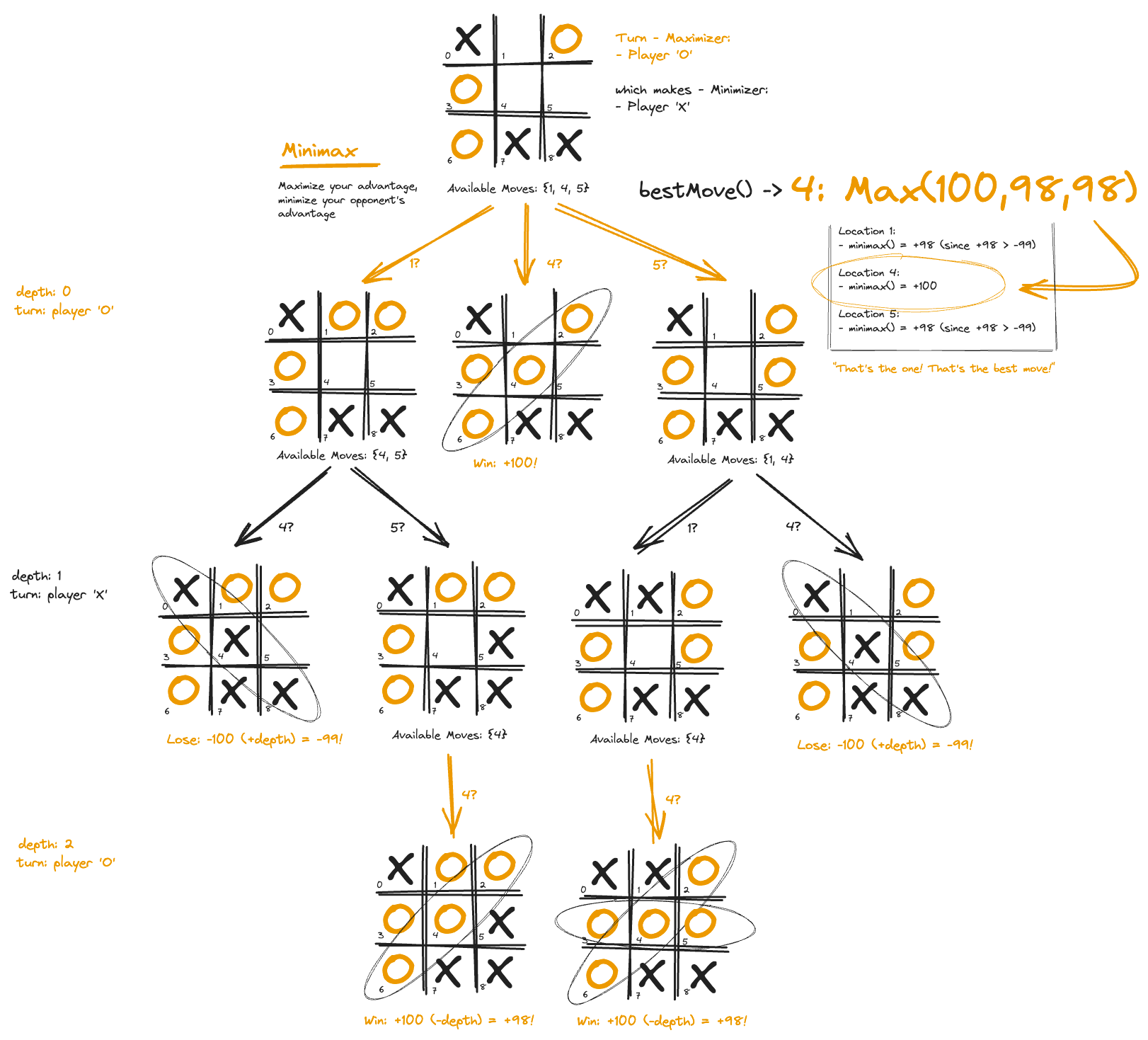
Tic-Tac-Toe using a minimax strategy to pick the next best move
Seen in full:
public final class Minimax implements BotStrategy {
private static final int MIN_SCORE = -100;
private static final int MAX_SCORE = 100;
private static final int DRAW_SCORE = 0;
private final String maximizer;
private final BotStrategyConfig config;
private final GameState initialState;
public Minimax(GameState state) {
this(state, BotStrategyConfig.empty());
}
public Minimax(GameState initialState, BotStrategyConfig config) {
this.initialState = initialState;
this.maximizer = initialState.currentPlayer();
if (initialState.playerMarkers().size() != 2) {
throw new IllegalArgumentException("Minimax requires exactly two players");
}
this.config = config;
}
public int bestMove() {
int bestMove = -1;
int maxScore = -Integer.MAX_VALUE;
for (int move : initialState.availableMoves()) {
var newState = initialState.afterPlayerMoves(move);
int score = minimax(newState, false, 0);
if (score > maxScore) {
maxScore = score;
bestMove = move;
}
}
return bestMove;
}
private int minimax(GameState state, boolean isMaximizing, int depth) {
if (state.hasChain(maximizer)) {
return MAX_SCORE - depth;
} else if (state.hasChain(opponent(maximizer))) {
return MIN_SCORE + depth;
} else if (!state.hasMovesAvailable() || config.exceedsMaxDepth(depth)) {
return DRAW_SCORE;
}
if (isMaximizing) {
int value = -Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = minimax(newState, false, depth + 1);
value = Math.max(value, score);
}
return value;
} else {
int value = Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = minimax(newState, true, depth + 1);
value = Math.min(value, score);
}
return value;
}
}
private String opponent(String playerMarker) {
return initialState.playerMarkers().stream()
.dropWhile(playerMarker::equals)
.findFirst()
.orElseThrow();
}
}So that’s it, right? Not quite. This is over-engineered tic-tac-toe, so although that traditionally means a two-player, zero-sum game on a 3x3 board, our over-engineered game is supposed to support n-player, any x any grid games which makes minimax limiting. Furthermore, as the board size increases, the number of possible moves increase exponentially making generating the bestMove using minimax computationally impractical without also introducing a limit on the depth the algorithm will search for future moves (which we limit using config.exceedsMaxDepth())
Minimax Strategy (w. Alpha-Beta Pruning)
A variation on pure minimax is to use alpha-beta pruning to only consider possibilities that are stronger that those already considered. The algorithm is implemented in the alphabeta() method of the AlphaBeta class. As with minimax this method recursively explores possible future game states, alternating between maximizing the score on the current player’s turn and minimizing on the opponent’s turn. The algorithm uses two values, alpha and beta, to prune (ignore) branches of the game tree that are guaranteed to be worse than already explored options. This pruning significantly reduces the number of game states that need to be evaluated, making the algorithm more efficient than vanilla minimax.
private int alphabeta(GameState state, boolean isMaximizing, int depth) {
return alphabeta(state, isMaximizing, -Integer.MAX_VALUE, Integer.MAX_VALUE, depth);
}
private int alphabeta(GameState state, boolean isMaximizing, int alpha, int beta, int depth) {
if (state.hasChain(maximizer)) {
return MAX_SCORE - depth;
} else if (state.hasChain(opponent(maximizer))) {
return MIN_SCORE + depth;
} else if (!state.hasMovesAvailable() || config.exceedsMaxDepth(depth)) {
return DRAW_SCORE;
}
if (isMaximizing) {
int value = -Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = alphabeta(newState, false, alpha, beta, depth + 1);
value = Math.max(value, score);
if (value > beta) {
break;
}
alpha = Math.max(alpha, value);
}
return value;
} else {
int value = Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int score = alphabeta(newState, true, alpha, beta, depth + 1);
value = Math.min(value, score);
if (value < alpha) {
break;
}
beta = Math.min(beta, value);
}
return value;
}
}The earlier you are in the game tree — with either only a few moves made or a larger than standard board, the more the benefits of this becomes apparent. A worked example is below:
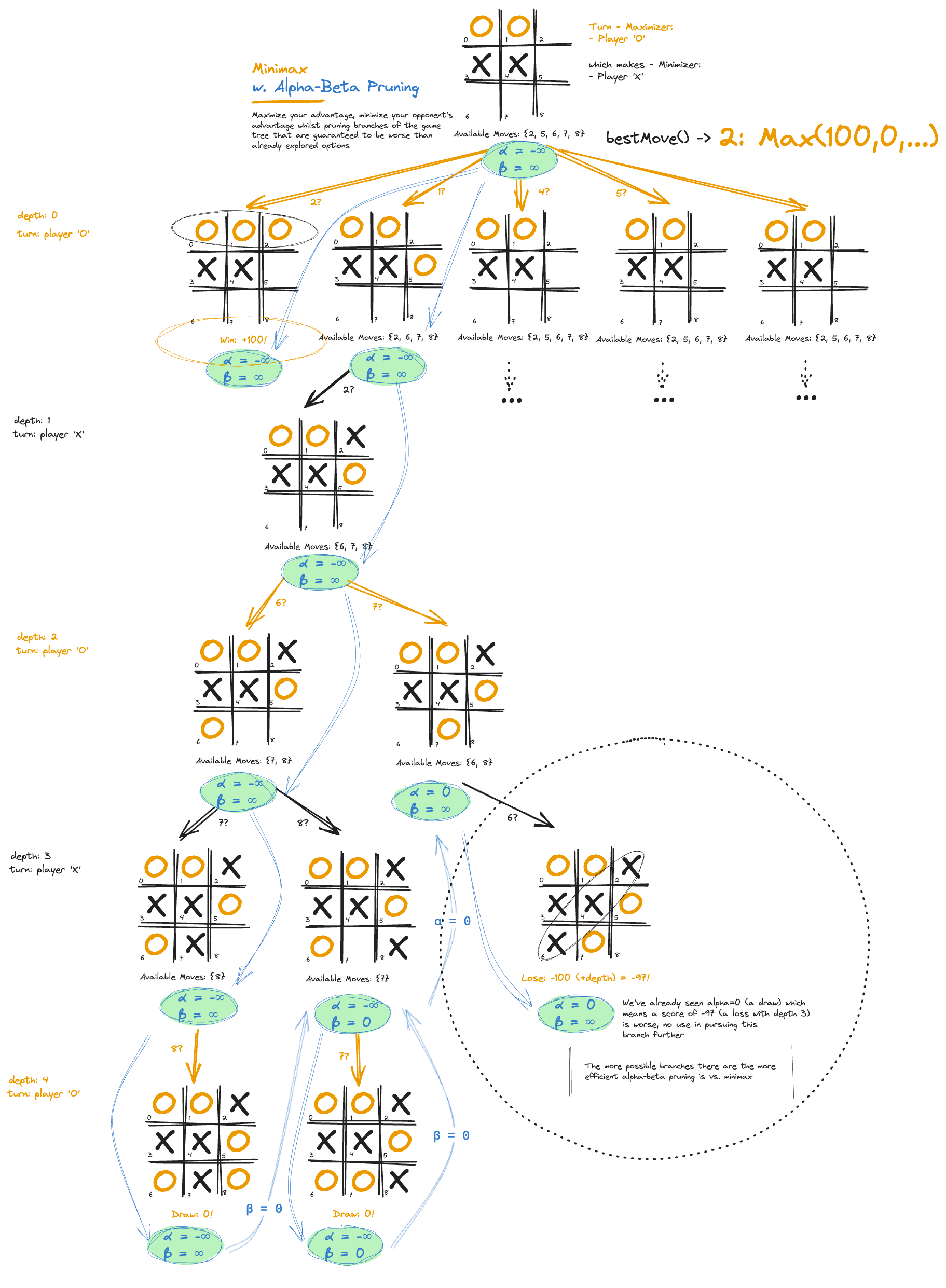
Minimax algorithm using Alpha-Beta pruning to reduce the size of the game tree to analyze
Unfortunately, even with all this new algorithmic magic we’re still limited to just two players. If only there was an algorithm like minimax that supported an arbitrary number of players instead of just 2. As it turns out there is: Enter Maxn — a generalization of the minimax algorithm for n-player games.
Algorithm Level 3
Maxn Strategy
Maxn is built to deal with games that involve three or more players, where the interactions are more complicated. While Minimax is designed for two-player games where one player’s gain is exactly the other player’s loss, what happens when there are 3 or more players?
In these games, the relationships between players aren’t strictly zero-sum; one player’s gain doesn’t necessarily mean the same amount of loss for another player.
Maxn extends minimax to handle these multi-player situations. It considers each player’s potential moves and strategies, not just focusing on a simple win-loss scenario, but rather on how each player’s actions affect all others. This allows Maxn to evaluate the move that maximizes the score for the current player.
To achieve its purpose, the MaxN class uses a recursive algorithm. The bestMove() method starts by considering all the available moves for the current player. For each move, it simulates making that move and then calls the maxn() method to evaluate the resulting game state.
public int bestMove() {
int bestMove = -1;
int[] maxScores = new int[numberOfPlayers()];
Arrays.fill(maxScores, Integer.MIN_VALUE);
for (int move : initialState.availableMoves()) {
var newState = initialState.afterPlayerMoves(move);
int[] scores = maxn(newState, 0);
log(move, scores, 0);
if (scores[newState.lastPlayerIndex()] > maxScores[newState.lastPlayerIndex()]) {
maxScores = scores;
bestMove = move;
}
}
return bestMove;
}The maxn() method then recursively explores all possible future moves for all players, up to a certain depth or until the game ends, producing a vector of best scores.
private int[] maxn(GameState state, int depth) {
if (state.lastPlayerHasChain()) {
int[] scores = new int[numberOfPlayers()];
Arrays.fill(scores, MIN_SCORE + depth);
scores[state.lastPlayerIndex()] = MAX_SCORE - depth;
return scores;
} else if (!state.hasMovesAvailable() || config.exceedsMaxDepth(depth)) {
return new int[numberOfPlayers()]; // Draw, all scores 0
}
int[] bestScores = new int[numberOfPlayers()];
Arrays.fill(bestScores, Integer.MIN_VALUE);
for (int move : state.availableMoves()) {
var newState = state.afterPlayerMoves(move);
int[] scores = maxn(newState, depth + 1);
if (scores[state.currentPlayerIndex()] > bestScores[state.currentPlayerIndex()]) {
bestScores = scores;
}
}
return bestScores;
}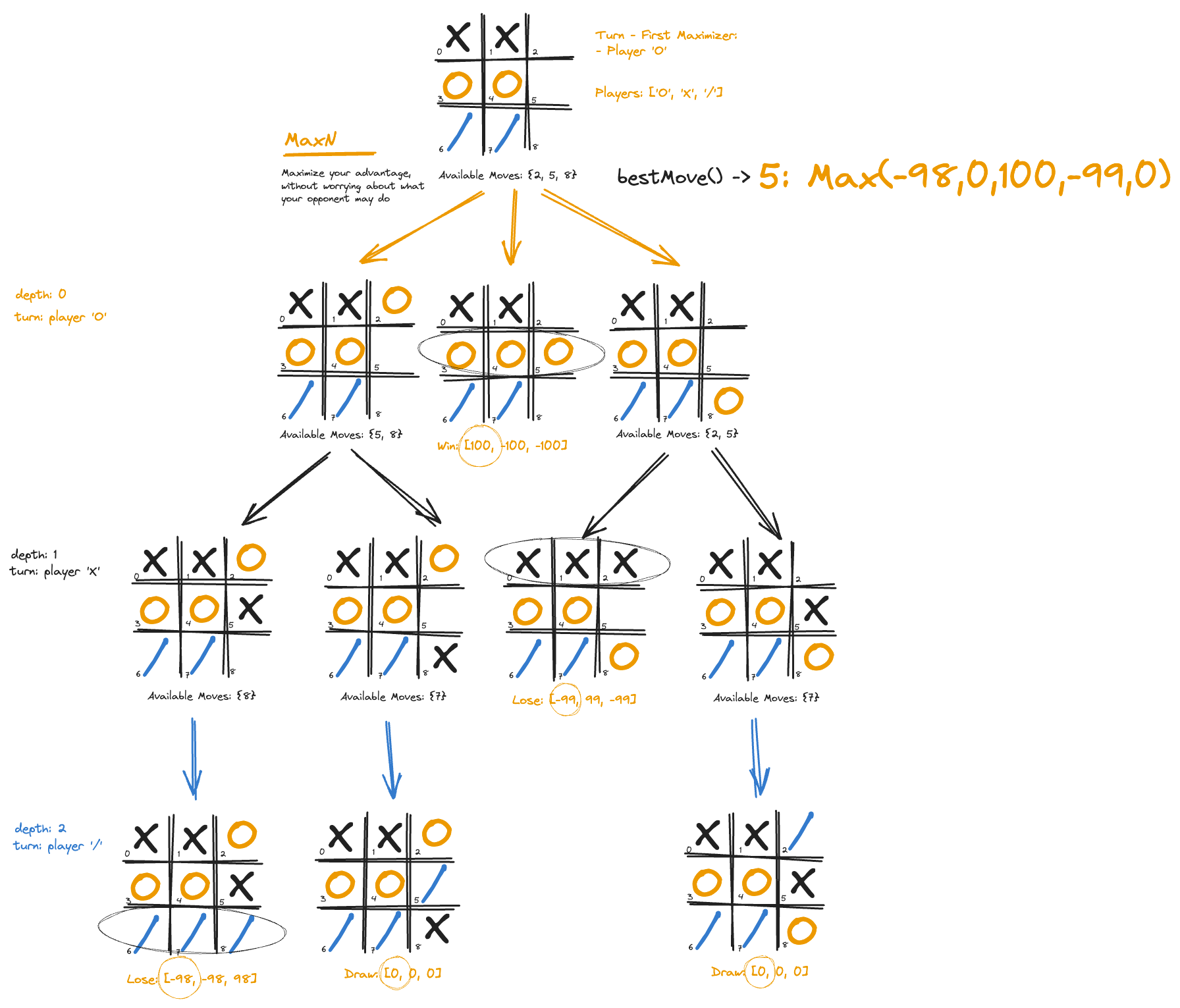
MaxN strategy applied to tic-tac-toe, which converges to Minimax in a two-player game
Paranoid Strategy
An alternative approach to MaxN which requires less computational resources for those larger multiplayer games is to assume everyone is out to get you. Paranoid is an AI so cautious, so on-edge, that it thinks everyone else in the game is out to get it. The Paranoid algorithm takes the complexity of multiplayer games and simplifies it in the most pessimistic way possible, effectively reducing the game to a two-player “me vs. the world” scenario.
By simplifying the game to a two-player scenario, we can potentially search deeper in the game tree with the same computational resources — essentially reducing the algorithm to a minimax search: the current player (maximizer) vs everyone else.
private int paranoid(GameState state, int depth) {
// Terminal state checks
if (state.hasChain(maximizer())) {
return MAX_SCORE - depth;
} else if (state.lastPlayerIndex() != maximizerIndex() && state.lastPlayerHasChain()) {
return MIN_SCORE + depth;
} else if (!state.hasMovesAvailable() || config.exceedsMaxDepth(depth)) {
return MIN_SCORE + depth;
}
if (maximizerIndex() == state.currentPlayerIndex()) {
// Our turn: maximize our score
int maxScore = -Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
GameState newState = state.afterPlayerMoves(move);
int score = paranoid(newState, depth + 1);
maxScore = Math.max(maxScore, score);
}
return maxScore;
} else {
// Opponent's turn: minimize our score
int minScore = Integer.MAX_VALUE;
for (int move : state.availableMoves()) {
GameState newState = state.afterPlayerMoves(move);
int score = paranoid(newState, depth + 1);
minScore = Math.min(minScore, score);
}
return minScore;
}
}The bestMove() method is similar to the one used by minimax:
public int bestMove() {
int bestMove = -1;
int maxScore = Integer.MIN_VALUE;
for (int move : initialState.board().availableMoves()) {
var newState = initialState.afterPlayerMoves(move);
int score = paranoid(newState, 0);
if (score > maxScore) {
maxScore = score;
bestMove = move;
}
}
return bestMove;
}A worked example shows interesting differences between how some of the other algorithms reach the goal, certainly with less computational resources.
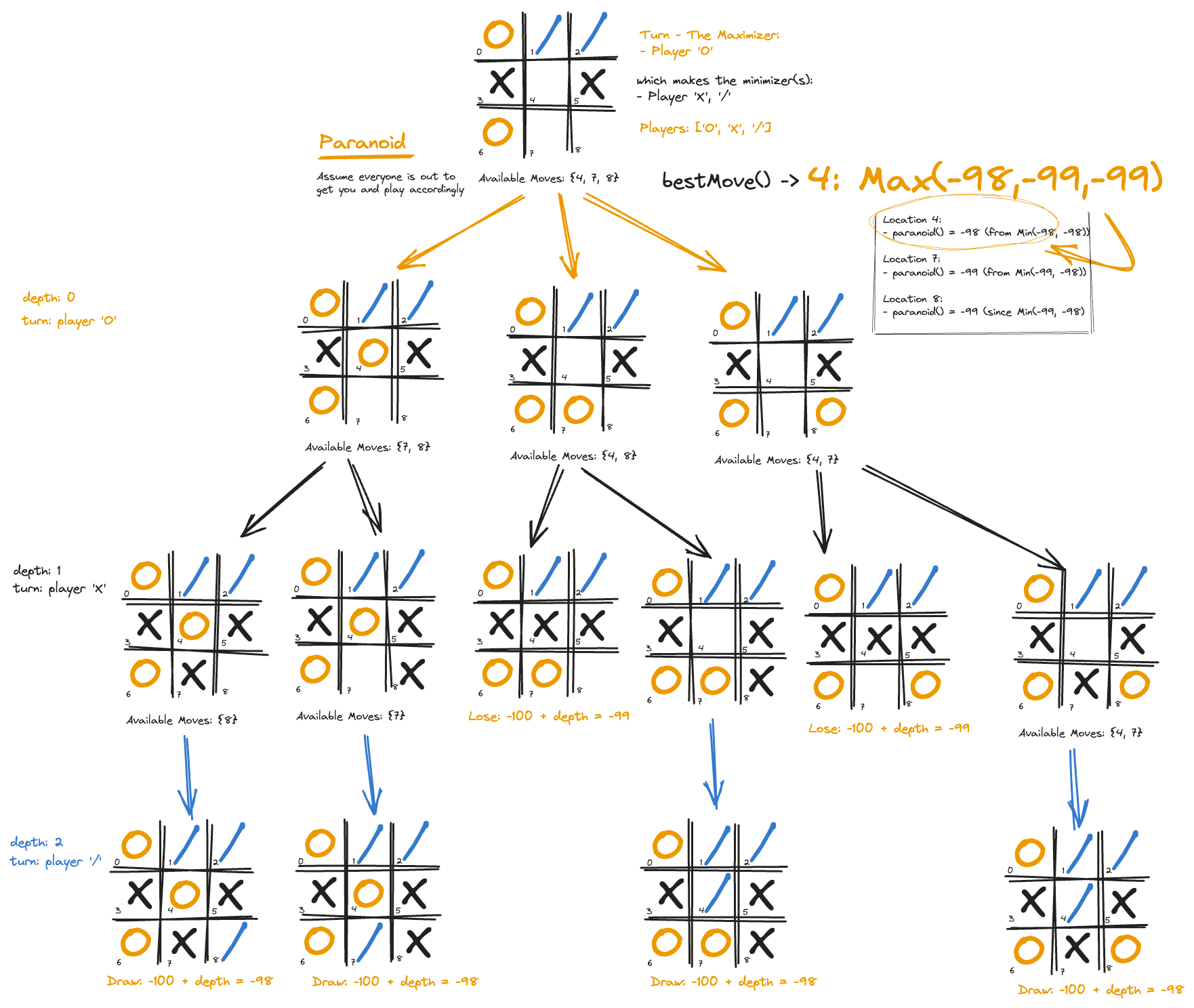
Paranoid Strategy for Tic-Tac-Toe reduces the game to “Me vs. The World”
The issue with most of the approaches so far is that we typically have to limit the depth the algorithm analyzes the game tree, or else wait days for it to complete its analysis when the board size grows — this may leave these algorithms blind to winning (or losing) strategies. Similarly in multiplayer games, predicting what everyone will do gets exponentially harder with each added player. We could, of course, as we did with minimax, improve upon the base algorithms with alpha-beta pruning, but that still faces similar limitations.
Can we solve for this issue in a way that is also easier to tune and configure? There is a class of powerful algorithms which improve with iterations or time. Enter Monte Carlo, named after the Monte Carlo Casino in Monaco, where the main developer of the method was inspired by his uncle’s gambling habits! Monte Carlo methods are ones I’m very familiar with having worked so long in financial risk management.
We come full-circle as “random” comes back, but this time in a useful way. It uses random sampling for deterministic problems which are difficult, uncertain, or impossible to solve using other approaches, is used across Science, Engineering, Finance, and a range of other disciplines.
Monte-Carlo methods mimic the trial-and-error learning process that we humans often use to achieve our goals — a process known as reinforcement learning
Algorithm Level 4
Monte Carlo Tree Search Strategy
This Monte Carlo approach to tic-tac-toe demonstrates how reinforcement learning concepts can be applied to game playing. The algorithm learns from experience (simulations) and gradually improves its decision-making, balancing between exploring new possibilities and exploiting known good strategies.
Here’s how it works: First, it takes the current game state and starts simulating possible moves. Then, for each of these moves, it plays out the rest of the game — not just once, but many, many times. It’s like speed-running through thousands of parallel universes of the game!
But wait, there’s more! As it’s zipping through these game simulations, it’s keeping score. Which moves led to more wins? Which ones were total busts? It’s building this incredible tree of knowledge, figuring out which branches are worth exploring further and which ones are dead ends, always ready to give its best move at any time as it’s learning.
And the best part? It doesn’t need to know all the strategic ins and outs of the game like other algorithms. It just needs to know the rules and then it learns the rest through sheer trial and error.
This is why Monte Carlo Tree Search is so powerful. It can tackle complex games that other algorithms struggle with, and it does it with style. It’s not just playing the game — it’s writing a playbook with each and every single move.
MonteCarloTreeSearch is our key class that implements a strategy for playing the game using the Monte Carlo Tree Search (MCTS) algorithm. The purpose of this code is to determine the best move for a player in a given game state using a configurable maximum time allowed for calculation. The MCTSNode class represents a node in the game tree. Each node keeps track of the game state, its parent node, child nodes, the number of times it has been visited, and the scores for each player.
public int bestMove() {
return monteCarloTreeSearch(initialState);
}
private int monteCarloTreeSearch(GameState state) {
MCTSNode root = new MCTSNode(state, null);
var startTime = System.currentTimeMillis();
while (!config.exceedsMaxTimeMillis(System.currentTimeMillis() - startTime)) {
MCTSNode node = treePolicy(root);
double[] reward = defaultPolicy(node.state);
backpropagate(node, reward);
}
return bestChild(root).state.lastMove();
}The algorithm works a little differently to those we’ve built to date — by building a tree of possible future game states and repeatedly simulating games from these states. It starts with the current game state as the root of the tree. Then, it follows these steps:
- Selection: It chooses a promising node in the tree to explore further. As it simulates, it balances exploration of new possibilities with exploitation of known good strategies, using the Algos, UCT, Upper Confidence Bound for Trees formula allowing it to make intelligent decisions even in complex game situations.
public MCTSNode select() {
MCTSNode selected = null;
double bestValue = Double.NEGATIVE_INFINITY;
for (MCTSNode child : children) {
double uctValue =
child.scores[state.currentPlayerIndex()] / child.visits
+ Math.sqrt(2 * Math.log(visits) / child.visits);
if (uctValue > bestValue) {
selected = child;
bestValue = uctValue;
}
}
return selected;
}2. Expansion: If the chosen node isn’t fully explored, it adds a new child node representing a possible next move.
private MCTSNode treePolicy(MCTSNode node) {
while (!node.state.isTerminal()) {
if (!node.isFullyExpanded()) {
return expand(node);
} else {
node = node.select();
}
}
return node;
}3. Simulation: It plays out a random game from the new node to its conclusion.
- The
treePolicy()method decides which node to explore next, balancing between exploring new possibilities and exploiting known good moves. - The
expand()method adds new child nodes to the tree, representing unexplored moves. - The
defaultPolicy()method simulates a random game from a given state to its conclusion, using our reward functiondefaultReward()to quantitatively reinforce promising paths through terminal states.
private MCTSNode expand(MCTSNode node) {
var untriedMoves = new ArrayList<>(node.state.board().availableMoves());
untriedMoves.removeAll(
node.children.stream()
.map(child -> child.state.lastMove())
.collect(Collectors.toList()));
int move = untriedMoves.get(new Random().nextInt(untriedMoves.size()));
var newState = node.state.afterPlayerMoves(move);
var child = new MCTSNode(newState, node);
node.children.add(child);
return child;
}
private double[] defaultPolicy(GameState state) {
var tempState = new GameState(state);
while (!tempState.isTerminal()) {
var moves = tempState.board().availableMoves();
int move = moves.get(new Random().nextInt(moves.size()));
tempState = tempState.afterPlayerMoves(move);
}
return defaultReward(tempState);
}
public double[] defaultReward(GameState state) {
var reward = new double[state.playerMarkers().size()];
int winningPlayerIndex = -1;
for (int i = 0; i < state.playerMarkers().size(); i++) {
if (state.board().hasChain(state.playerMarkers().get(i))) {
winningPlayerIndex = i;
break;
}
}
for (int i = 0; i < state.playerMarkers().size(); i++) {
if (i == winningPlayerIndex) {
reward[i] = MAX_SCORE;
} else if (winningPlayerIndex != -1) {
reward[i] = MIN_SCORE;
} else {
reward[i] = DRAW_SCORE;
}
}
return reward;
}4. Back-propagation: It updates the statistics of all nodes in the path from the new node back to the root based on the game’s outcome. Here, transforms the abstract idea of “good moves” into concrete statistics by repeatedly simulating games and aggregating their results up the game tree.
private void backpropagate(MCTSNode node, double[] reward) {
while (node != null) {
node.visits++;
for (int i = 0; i < initialState.playerMarkers().size(); i++) {
node.scores[i] += reward[i];
}
node = node.parent;
}
}These steps are repeated many times within the allowed time limit. The more iterations, the more improved our algorithm’s decision-making becomes.
Finally, the bestChild() method selects the most promising move at the end of all simulations.
private MCTSNode bestChild(MCTSNode node) {
return node.children.stream().max(Comparator.comparingDouble(c -> c.visits)).orElseThrow();
}Visualizing a few worked scenarios we see how impressive this technique is especially with the UCT formula ensuring we have the right balance between exploration and exploitation:
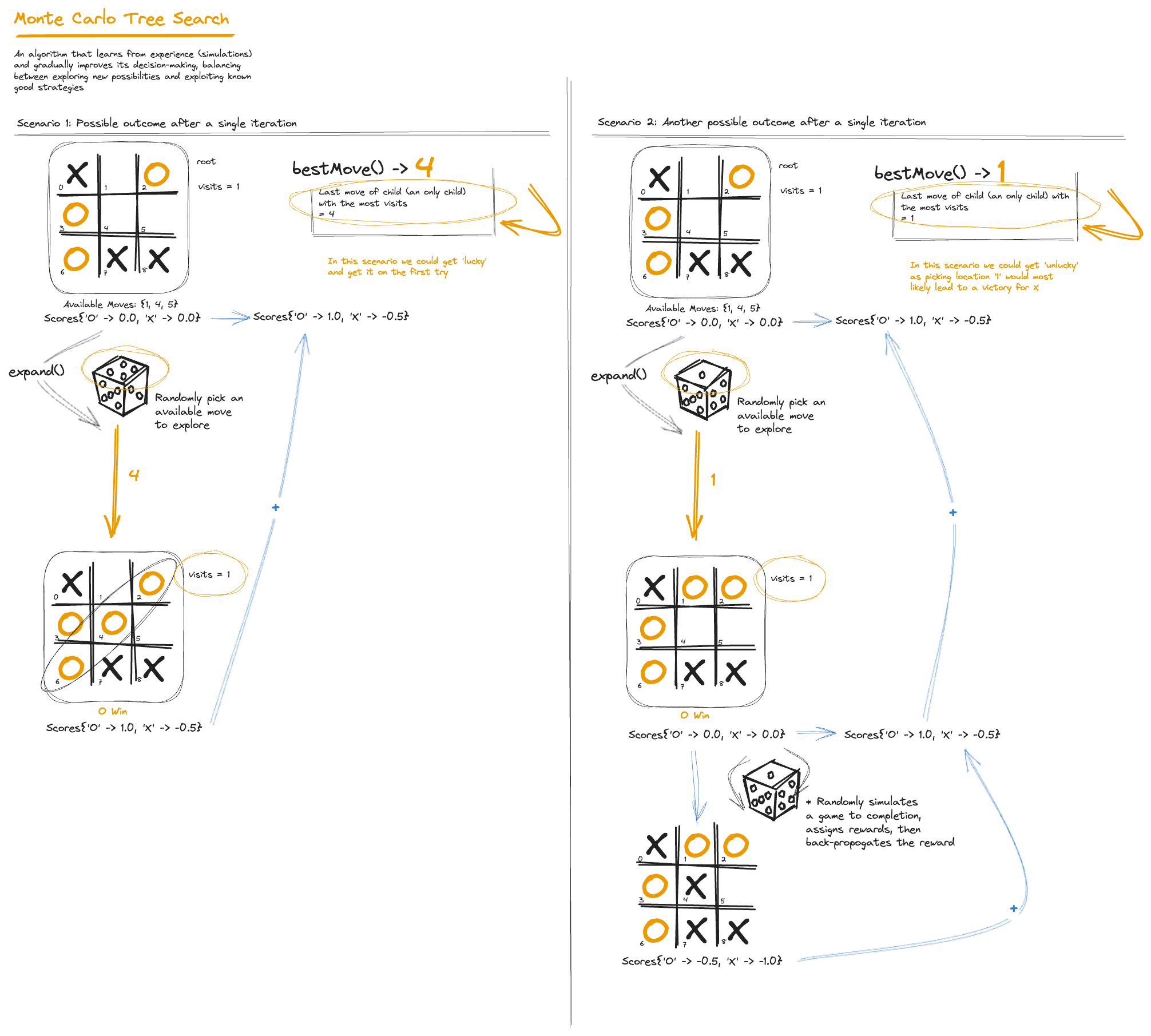
Monte Carlo Tree Search with a low number of iterations is about as good as our level 1 Algorithm: Random
With more iterations MCTS becomes more confident of the right path to choose.

Monte-Carlo Tree Search applied to Tic-Tac-Toe makes efficient use of computational resources to beat out our other algos
And there we have it. A game as simple as Tic-Tac-Toe, is transformed from a naive newbie to an all-powerful game AI. So the next time you’re playing a multiplayer game and the AI seems suspiciously good at surviving against all odds, remember: you might be up against one of these algorithms!
Disclaimer:
The views and opinions expressed in this blog are based on my personal experiences and knowledge acquired throughout my career. They do not necessarily reflect the views of or experiences at my current or past employers
References
- M. P. D. Schadd and M. H. M. Winands, “Best-Reply Search for Multi-Player Games”.
- N. Sturtevant, M. Zinkevich, and M. Bowling, “Prob-Maxn: Playing N-Player Games with Opponent Models”.
- A. M. Nijssen and M. H. M. Winands, “An Overview of Search Techniques in Multi-Player Games”.
- M. Świechowski, K. Godlewski, B. Sawicki, and J. Mańdziuk, “Monte Carlo Tree Search: a review of recent modifications and applications,” Artif Intell Rev, vol. 56, no. 3, pp. 2497–2562, Mar. 2023, doi: 10.1007/s10462-022-10228-y
- S. J. Russell and P. Norvig, Artificial intelligence : a modern approach. Pearson, 2016. Available: https://thuvienso.hoasen.edu.vn/handle/123456789/8967. [Accessed: Aug. 27, 2024]